A complex system that works is invariably found to have evolved from a simple system that worked. A complex system designed from scratch never works and cannot be patched up to make it work. You have to start over with a working simple system.
— John Gall, Systemantics: How Systems Work and Especially How They Fail (1975)
Gall’s Law: From Architectural Nightmares to Evolutionary Success
Imagine you’re the lead on a software project and someone insists on tearing down the existing code to build a brand-new system from scratch. After three years of work, you release it – only to see competitors overtake you and your market share collapse. That’s exactly what happened to Netscape in the late 1990s. Netscape 6.0 launched years behind schedule because the team chose a “Big Bang” rewrite of their browser, which Joel Spolsky later called “the single worst strategic mistake any software company can make: [to] rewrite the code from scratch”. By the time they shipped, Microsoft had already eaten their lunch. This story is an archetypal architectural nightmare – wasted time, frustrated developers, and a product that barely functions.
The root cause of such disasters was summarized decades earlier by physician‐turned‐systems theorist John Gall. In his 1975 book Systemantics, Gall famously observed that “a complex system that works is invariably found to have evolved from a simple system that worked. A complex system designed from scratch never works and cannot be patched up to make it work. You have to start over with a working simple system.” [1]. In short, any intricate software solution we think we can meticulously specify up front is almost guaranteed to fail. Only by starting with a small, functioning core and gradually growing it can we build reliable complexity.
Gall’s Law underpins the modern push for iterative development and modularity. It explains why the World Wide Web and the blogosphere – systems that grew bit by bit from humble beginnings – succeeded where grandiose visions like CORBA (the Common Object Request Broker Architecture) failed. The law essentially says: treat complexity as a badge earned by evolution, not a design goal.
Why Complexity Built Upfront Fails
Large, monolithic designs often suffer from hidden assumptions and untested interactions. When architects imagine a system “in full glory”, they can’t possibly foresee every data flow, user scenario, or integration issue. Without real feedback, the system balloons in tangled dependencies. Gall’s law highlights feedback loops and modularity as saviors: by building a simple version first, each new feature or module can be tested in context, refined, and reassembled. This aligns with agile and lean principles: start simple, validate, then expand.
Conversely, when a team tries to deliver all features at once, any unknown flaw is deeply buried. The system’s parts weren’t allowed to prove themselves independently. There are no quick feedback loops. When a subsystem doesn’t work as expected, fixing it can trigger unforeseen breakages elsewhere. In Gall’s words, you will often have to “start over” with a simpler base. In practice, that means heavy cost: rework, wasted resources, and missed market opportunities.
Real-World Failures: When Gall’s Law Was Ignored
- Netscape 6.0 (1999): Netscape’s developers spent three years rewriting their browser from the ground up, leaving long-time users with an outdated version. As Joel Spolsky recounts, this was exactly the “single worst strategic mistake”: a full rewrite that simply didn’t work [1]. They effectively fell victim to Gall’s Law – the new version never reached the reliability or features of the old code base, forcing them to limp along with legacy code while competitors innovated.
- FBI’s Virtual Case File (VCF) (2002–2005): The FBI’s effort to replace paper case files with a digital “Virtual Case File” system cost over $170 million and was ultimately abandoned [2]. Investigations later pointed out that FBI leadership treated this as a straightforward digital conversion, not realizing it required a profound change in work processes. They attempted a waterfall‐style redesign of the entire case-management system. By the time they uncovered its flaws, millions of lines of code had been written that simply didn’t meet the real needs. The VCF project is often cited in government IT as a cautionary tale: don’t attempt a colossal “big bang” transformation without iterative feedback.
In both cases, teams underestimated how tightly coupled and sensitive large systems are. Without a simple working core to iterate on, small errors amplify. As Gall noted, “we consistently fail to create large-scale systems that work as well as, say, gravity or photosynthesis” when we jump straight to ambitious designs.
Success Stories: Growing by Evolution
Gall’s law isn’t just a lament; it’s a prescription. Many modern systems have thrived because they evolved from modest beginnings:
- Amazon (circa 2002–): Amazon famously started as an online bookstore – a simple web app with one core function (selling books). Instead of rewriting for each new business line, Jeff Bezos mandated in 2002 that all teams expose their functionality through service APIs [3]. This Bezos API Mandate forced Amazon to break its monolith into small, independently deployable services. Each team (often a “two-pizza team”) owned a specific service or subdomain (e.g. order management, recommendations, inventory), and communicated only through explicit interfaces. This is precisely the “stream-aligned” microservices model:
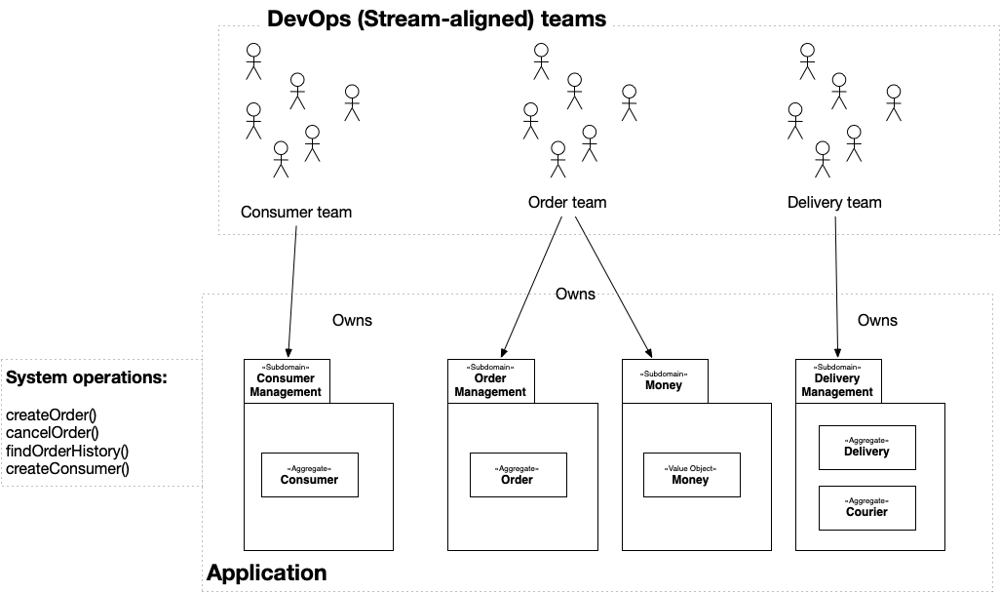 Figure: In a microservices organization, each DevOps (stream-aligned) team owns one business subdomain (service). By starting with a core bookstore system and gradually adding services via APIs, Amazon was able to scale and expand (to toys, electronics, AWS, etc.) without a single colossal rewrite.
Figure: In a microservices organization, each DevOps (stream-aligned) team owns one business subdomain (service). By starting with a core bookstore system and gradually adding services via APIs, Amazon was able to scale and expand (to toys, electronics, AWS, etc.) without a single colossal rewrite.
By 2006 Amazon had dozens of such services; today it has hundreds. Each new feature was built on top of a minimal working system. For example, Amazon Prime and AWS emerged as separate services layered on existing order/payment systems. Crucially, Amazon did not attempt one redesign to cover all use cases; they let proven services become building blocks for more complex functionality. As the Nordic APIs blog notes, this simple practice of externalizing every feature was “at the core of why Amazon was able to scale so dramatically in a short window of time” [3].
-
Netflix (late 2000s–2010s): Netflix’s platform followed a similar evolution. In its early days (late 1990s/2000s) Netflix was a DVD-by-mail service with a single monolithic application handling user accounts, recommendations, billing, and inventory. This sufficed for a few hundred thousand users, but as streaming took off, this monolith became a bottleneck. A major database outage in 2008 drove Netflix to split its platform into many microservices. They built a mature ecosystem (Eureka for service discovery, Hystrix for fault tolerance, Zuul API gateway, etc.) and by the early 2010s had hundreds of independently deployable services (for user profiles, video playback, personalization, billing, etc.). Each service could fail without collapsing the whole system. [4] As Netflix scaled, it discovered diminishing returns from endless sprawl. Today it operates a hybrid model: many microservices for decoupling, but also some larger “modules” for efficiency. Even so, Netflix’s growth was all by iteration. They didn’t design Netflix at scale up front – they rebuilt it one piece at a time, always starting from the working parts.
-
Linux Kernel (1991–present): The Linux operating system is a classic open-source success story. Linus Torvalds began Linux in 1991 as a small hobby: just two processes printing letters “A” and “B” on the screen to demonstrate multitasking. Over months he expanded that tiny kernel with drivers, file systems, and basic utilities. By late 1991 Linux could actually boot and run tasks, reading the web via dial-up. Every subsequent year saw incremental improvements: virtual memory by Christmas 1991, the X11 graphical server by 1992, and so on. Crucially, each new feature was added to an already-working system. Linux was never the product of one grand design from the outset – it was grown. Today’s billion-line kernel is the result of 30+ years of iterative expansion on that early core, embodying Gall’s Law in practice.
These examples reinforce Gall’s insight: complex, reliable systems are a byproduct of evolution, not engineering fiat. Now let’s turn that insight into actionable advice.
A Senior Engineer’s Playbook
How do we apply Gall’s Law in day-to-day engineering? The goal is always to keep our system working at every step. Here are key practices:
- Start with an MVP (Minimum Viable Product) [5]: Build only the essential core that proves your concept. Don’t try to predict every feature or scale requirement up front. For example, Amazon famously launched with just books, not “everything store”. As Atlassian explains, an MVP is “the simplest version of a product that allows teams to validate ideas and gather feedback with minimal effort”. An MVP reduces risk by forcing you to confront real requirements early. Once the core works, gather user feedback and expand. This iterative MVP approach is the embodiment of Gall’s Law: ensure the simple system works first, then add complexity.
- Instrument for Feedback (Tracing & Observability): When your system is composed of many parts, you need visibility into how they behave in production. Distributed tracing is a critical tool for this. In a microservices architecture, a single user request may hop through dozens of services. Without tracing, it’s impossible to see where the bottleneck or bug lies. As a recent guide notes, distributed tracing “allows developers to observe and analyze the flow of requests across multiple services” [6]. You can then pinpoint performance bottlenecks, improve end-to-end visibility, and diagnose issues faster. In practice, use open telemetry or APM tools (e.g. Jaeger, Zipkin, AWS X-Ray) so that every feature you add or change is covered by logs and traces. This continuous feedback loop ensures that as the system grows, you catch problems early, staying true to Gall’s Law by evolving the system under observation.
- Use Feature Flags (Feature Toggles): Don’t unleash a half-finished feature on all users at once. Wrap new functionality behind feature flags so you can turn it on or off at will. Feature toggles let you ship new code paths in the main branch without exposing them in production until they’re ready. Martin Fowler describes toggles as “a powerful technique, allowing teams to modify system behavior without changing code” [7]. In practice, deploy with a flag off, then gradually enable it (e.g. for internal users, then a random subset, then 100%). If something goes wrong, you simply flip the flag off again (acting as a “kill switch”). This way, you can incrementally evolve the system by carving out new features from working functionality, rather than destabilizing the entire architecture. Feature flags are especially valuable in large systems where real-world usage can reveal problems that tests miss.
- Refactor Continuously: Code that worked yesterday may become fragile as requirements change. The antidote is constant refactoring – small, behavior-preserving changes that keep the codebase clean and adaptable. As Martin Fowler puts it, refactoring is “a change made to the internal structure of software to make it easier to understand and cheaper to modify, without changing its observable behavior”. Good teams refactor every time they add a feature or fix a bug: restructure interfaces, eliminate duplication, and improve naming. Fowler advises that refactoring is part of day-to-day programming: before adding new logic, first improve any confusing existing code to make the addition straightforward. This means your simple system can safely evolve. By contrast, neglecting refactoring leads to a rigid codebase that resists change, effectively violating Gall’s Law by pretending a complex design from years ago still works. Always keep the code as simple as possible to express current needs, so the system can continue to evolve reliably. [8]
- Keep Components Small and Decoupled: Whenever possible, slice your system by feature or domain. Following Netflix and Amazon’s lead, let each service or module own a narrow responsibility. Smaller components mean fewer unknowns and simpler testing. They also fit on a single developer’s screen or a small team’s purview. Avoid design-time coupling (no shared databases or global state) – only allow communication through explicit APIs or messages. This technical discipline enforces Gall’s Law: it guarantees each piece started simple and can change independently as requirements grow.
References
- From Gall’s Law to Gaul’s Law
- The FBI’s Dangerous Failure to Adapt to the Digital Age
- The Bezos API Mandate: Amazon’s Manifesto For Externalization
- How Netflix’s Architecture Evolved: From Monolith to Microservices and Toward a Hybrid Mode
- What is a Minimum Viable Product (MVP)? How to get started
- Distributed Tracing in Microservices: A Comprehensive Guide
- Feature Toggles (aka Feature Flags)
- Refactoring